An obscure reason of GPU memory leak in pytorch
08 May 2023Recently I am transfering some of my prvious tensorflow and jax codes into pytorch. About the comparison between the three frameworks, we could have another 10 blogs to argue, but that is not what I want to share today.
During the testing of my torch codes, I noticed the allocated cuda memory kept increasing as the training loop went. And apparently I didn’t make any obvious mistakes like appending my loss term to the log before itemizing it.
So driven by my curiosity and perfectionism, I decided to debug my codes line by line, and finally find this largely unnoticed issue:
If x is a non-leaf tensor, e.g. x is the output of a linear layer, in-place operations like
x /= torch.norm(x, dim=-1, keepdim=True)
will cause the memory leak issue and keep increasing the memory every time you call this line.
How to solve?
Changing the line to
x = x / torch.norm(x, dim=-1, keepdim=True)
will totally solve the issue.
The above issue is super easy to reproduce in both 1.13 and 2.0, as shown in the following picture:
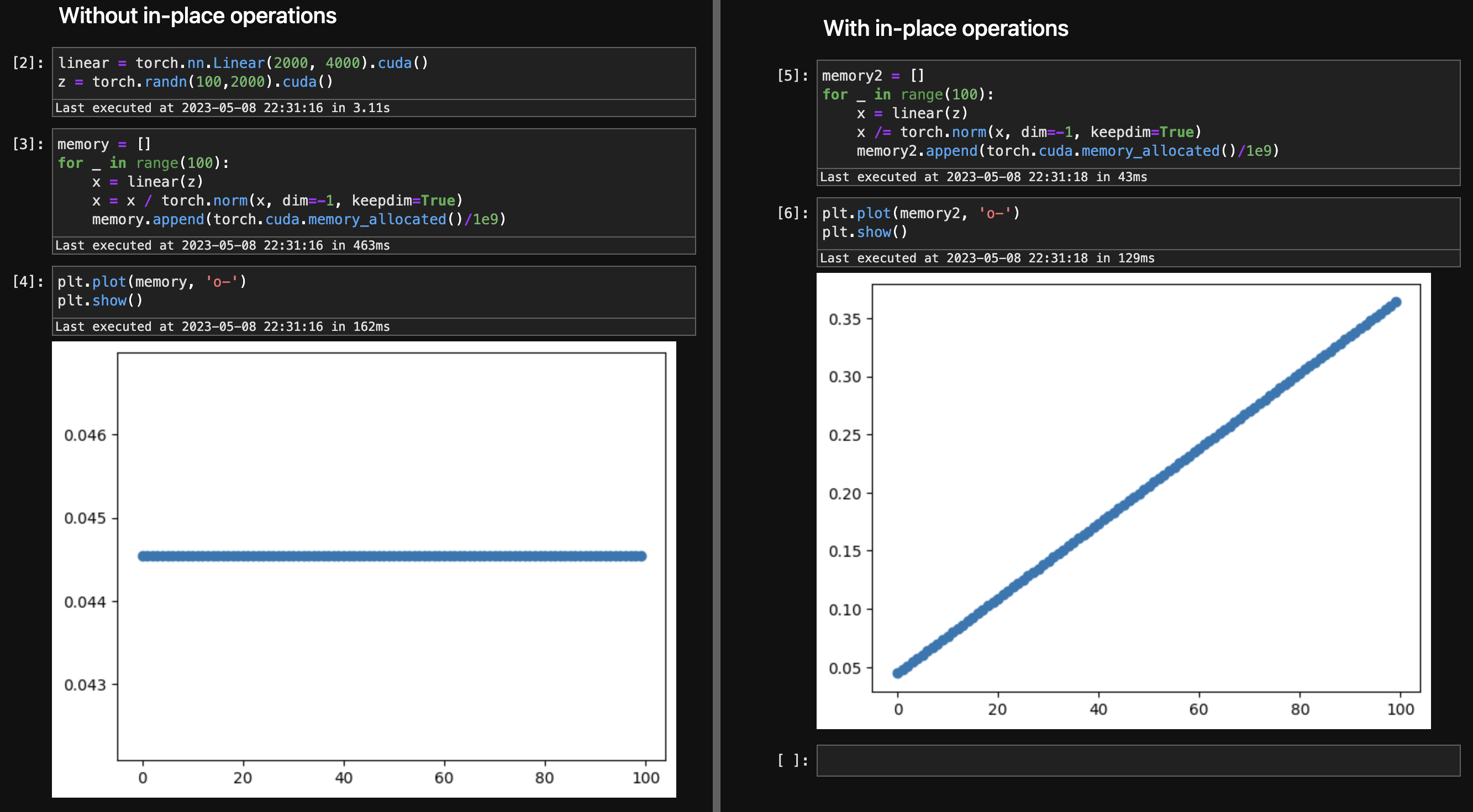
So, the takeaway is: avoid in-place operations in your pytorch computing graph.